Motivation

两种翻译系统中可能出现的问题。
- 一个词被翻译成不连续的片段 (新生银行 -> new … bank)
- 过度翻译 (两个女孩 -> two girls and two girls)
这些都是未遵循原文的句法信息导致的问题。作者认为可以通过整合源端syntax信息来减轻这些问题。
Methods
模型说明
syntax信息用线性表示的句法树来描述
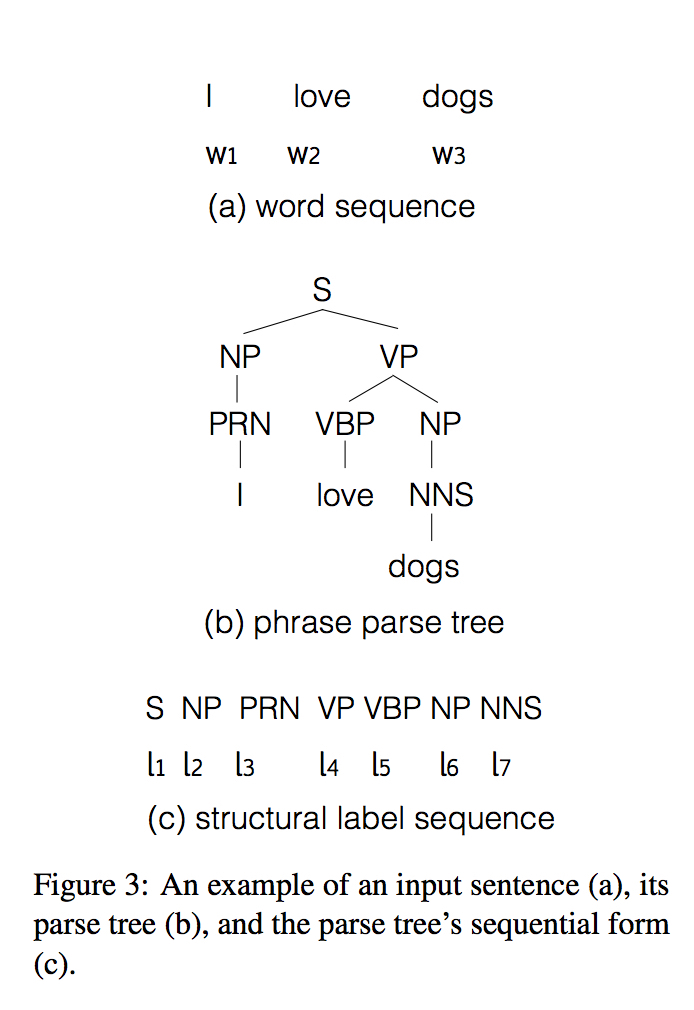
模型主要考虑如何在encoder端加入syntax信息,尝试三种方法:
- Parallel: 分别编码词和句法两个序列,然后连缀
- Hierarchical: 两层RNN,底层为句法序列,上层为词序列
- Mixed: 将词和句法序列按顺序混合(即语法解析树深度优先遍历),将词所在位置的隐状态作为decoder的输入
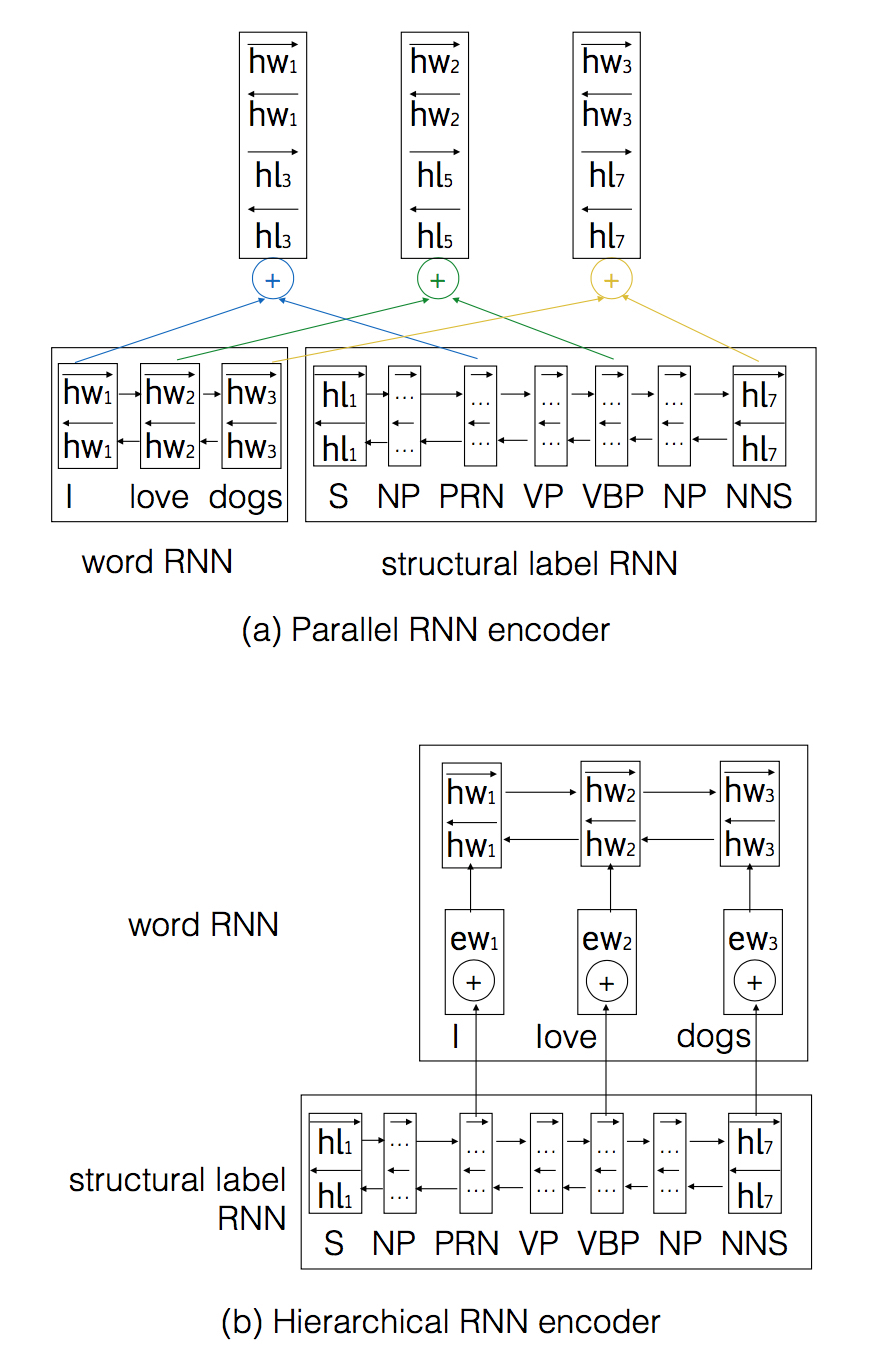

模型比较
词序列和句法序列结合程度: Parallel > Hierarchical > Mixed
Mixed最简单,统计表明序列长度平均变为词序列长度的3倍
Experiments
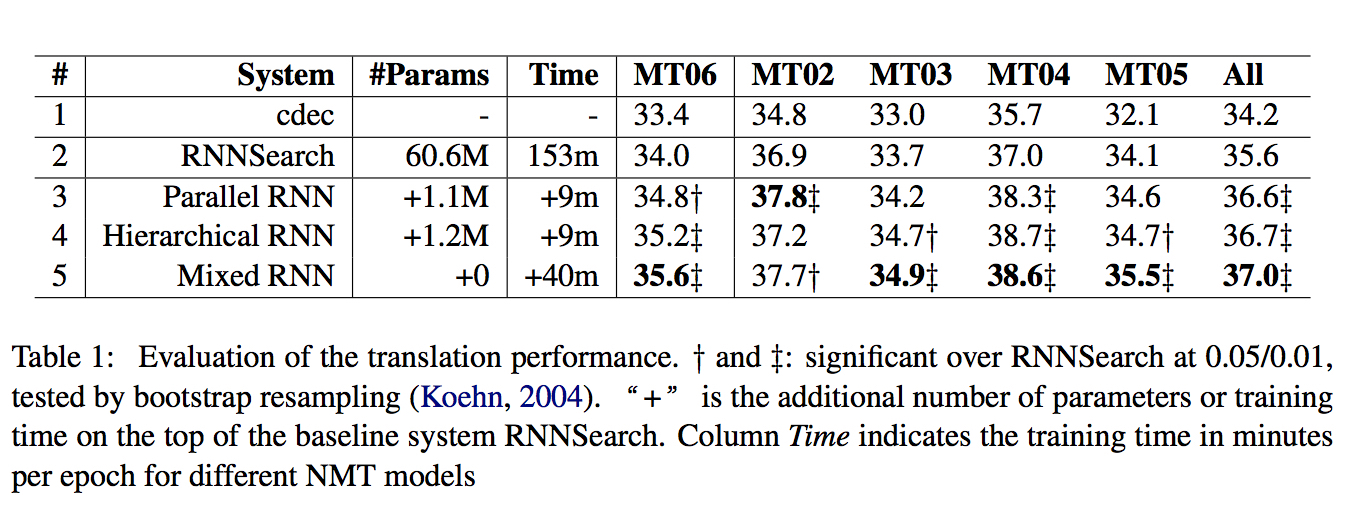
总体来说都有提升,其中Mixed模型最简单但效果最好,下面的实验分析也是对比RNN search和Mixed.
分析
Long Sentences
- 在各种长度的句子上均有提升
- NMT系统在超过长度设定(文中为50)时效果极差,可能原因有:(1) 模型不能适应长度超过限定的句子的翻译 (2) 系统对长输入序列倾向于较早停止
Word Alignment
结合句法信息,能够降低alignment error rate(AER)
Phrase Alignment
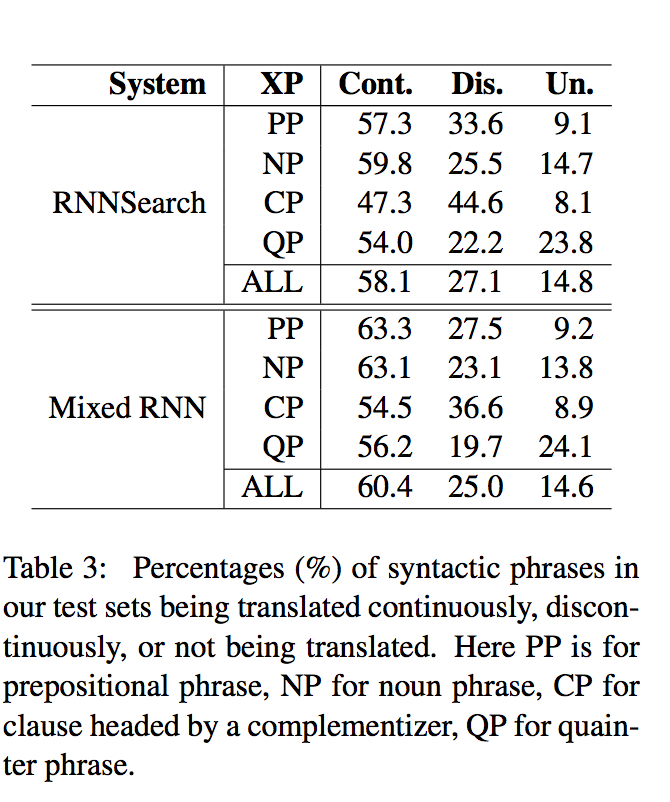
注:Cont.表示连续翻译,Dis.表示不连续翻译,Un.表示未翻译
Over Translation
介绍了ratio of over translation (ROT):
即重复总次数/总词数
实验中,ROT从5.5%降低到4.5%
Rare Word Translation
- 能更好的将稀有词翻译成UNK
- 能够兼容subword方法,在拆分词的同时拆分POS节点即可
Questions
- 文中模型依赖POS标注的预处理,会不会有错误传播?能不能做joint任务?